Approaching System Design
Decide the core and build your system around it. Core is use-case specific and it could be a database, communication protocol, or any other must-have component.
Another good approach:
- start with day 0 architecture
- see how next component would behave at next scale
- re-architect
- repeat
Designing an Online-Offline Indicator
Storage: user (int) ----⇒ online/offline (boolean)
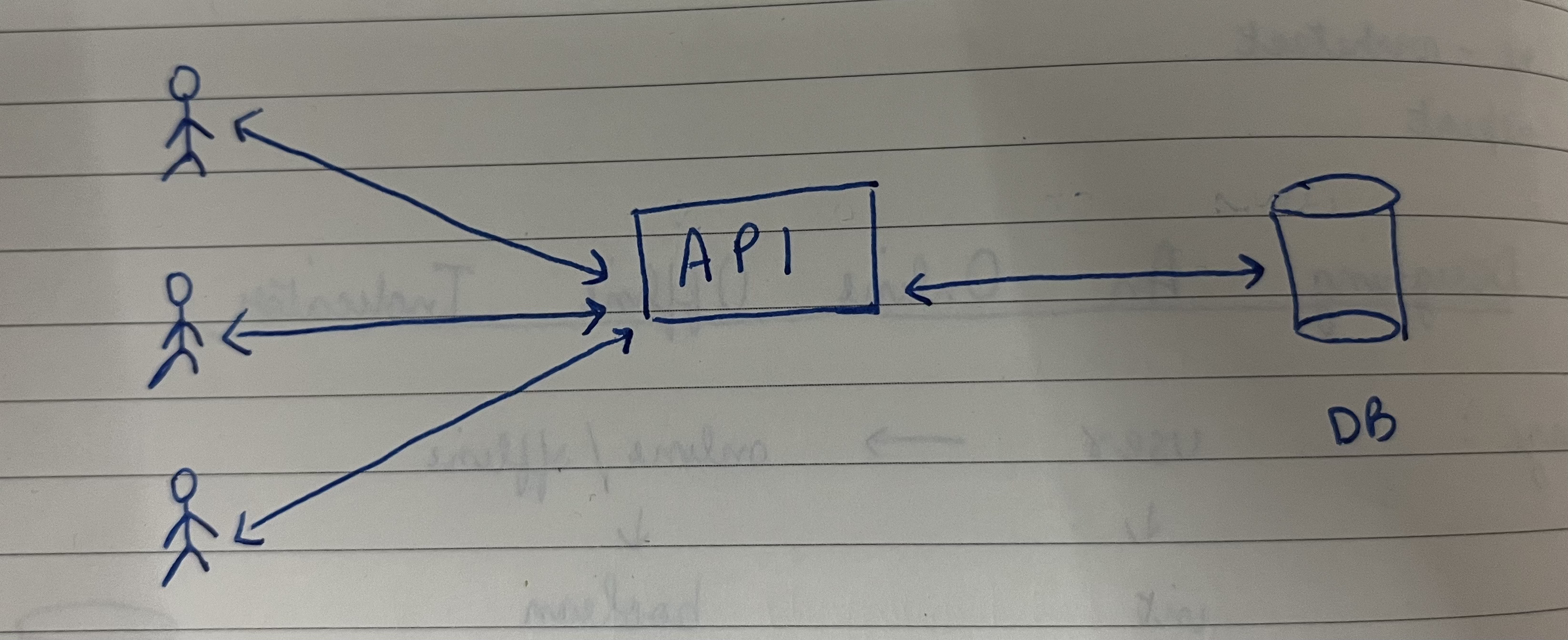
Interfacing API
GET /status/users?ids=u1,u2,u3 → this api returns statuses for the user ids.
Updating the Database
Push based model: Users push their status periodically. It’s called a “heartbeat”.
POST /heartbeat → the authenticated user will be marked “alive”
So, when is the user offline? When we do not receive heartbeat for long enough (which is subjective).
pulse
| user_id | last_hb |
|---|---|
| u1 | 1000 |
| u2 | 2000 |
When we receive heartbeat:
UPDATE pulse
SET last_hb = NOW()
WHERE user_id = u1;- user sends heartbeat every 10 seconds.
GET /status/user_id
- if no entry in the db → offline
- if entry and entry.last_hb < NOW() - 30 → offline
- online
Estimating Scale
100 users → 100 entries 1B users → 1B entries
user_id (int - 4B) → last_hb (int - 4B) size = 8B
1B entries = 8GB
Can we do better on storage? If user is not present in db, we return offline. So, let’s expire the entries after 30 seconds.
Thus, total entries = active users
We need a DB with KV + expiration → Redis → DynamoDB
If we get a new requirement to show the last active time of the user, we can no longer auto-expire and will have to store data for all users.
Foundational Topics in System Design
Database
- storing text as
longtextstores large text as a reference instead of storing the data in the same row varcharis used to short text which is stored with the other columns- using
datetimeis convenient, but suboptimal and heavy on size and index - storing datatime as epoch integer is efficient, lightweight and optimal
- custom format is also a good option for readability
Caching
- reduces response time by saving any heavy computation
- caching is not only RAM-based
- typical use: reduce disk I/O or Network I/O
- caches are just glorified hash tables (with some advanced data structures)
Scaling
- ability to handle large number of concurrent requests
- scaling strategies:
- vertical scaling (hulk) - make infra bulky by adding more CPU/RAM
- easy to manage
- risk of downtime
- horizontal scaling (minions) - add more machines
- complex architecture
- network partitioning
- fault tolerance
- vertical scaling (hulk) - make infra bulky by adding more CPU/RAM
- horizontal scaling = infinite scaling, but with a catch. Stateful components like DB and cache can handle only a certain amount of concurrent requests. Hence, always scale bottom up (DB first, then API server)
Delegation
- what does not need to be done in realtime should not be done in realtime
- core idea: delegate and respond
- tasks that are delegated:
- long running tasks (spin up EC2)
- heavy computation query
- batch and write
- anything that could be eventual
Concurrency
- to get faster execution
- threads
- multiprocessing
- issues with concurrency
- communication between threads
- concurrent use of shared resources like DB and in-memory variables
- handling concurrency
- locks
- mutexes and semaphores
- we protect our data through
- transactions
- atomic instructions
Communication
- in usual communication, the client sends a request to the server (which does the heavy lifting) and this communication is kept open with a timeout
- in short polling, the client polls the server every few seconds
- refreshing cricket score
- checking if server is ready
- in long polling, the connection is kept open and the server only sends response when done
- websocket is a birectional channel which is kept open and server can proactively send data to the client
- server side event - unidirectional communication in which server proactively sends data to client